for packet in cc1_cap: try: source_ip = packet.ip.src if source_ip notin target and source_ip notin get_except: cc1_list.add(source_ip) except AttributeError: pass
for packet in cc2_cap: try: source_ip = packet.ip.src if source_ip notin target and source_ip notin cc1_list: cc2_list.add(source_ip) except AttributeError: pass
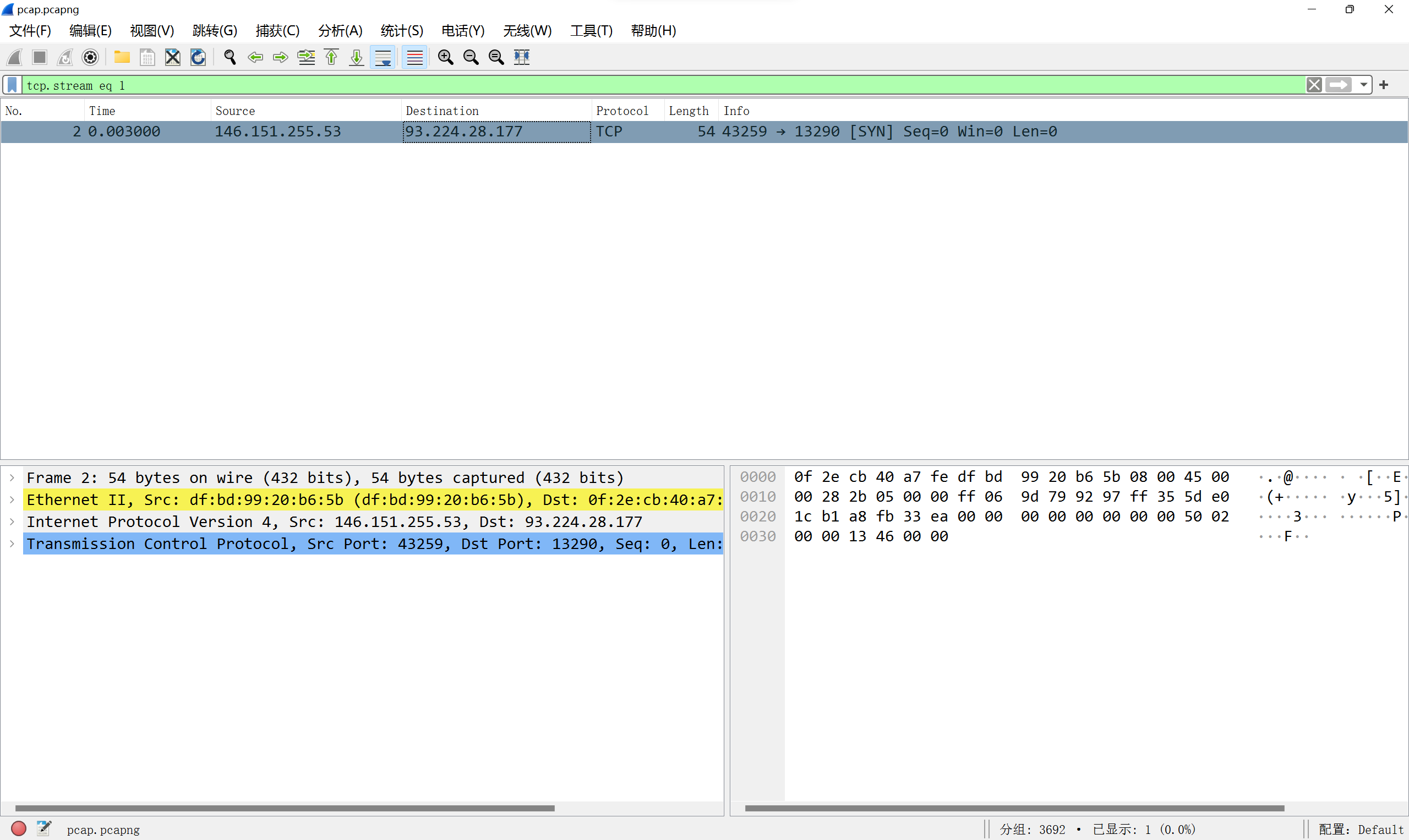
for packet in syn_cap: try: source_ip = packet.ip.src if source_ip notin target and source_ip notin cc2_list and source_ip notin cc1_list: syn_list.add(source_ip) except AttributeError: pass
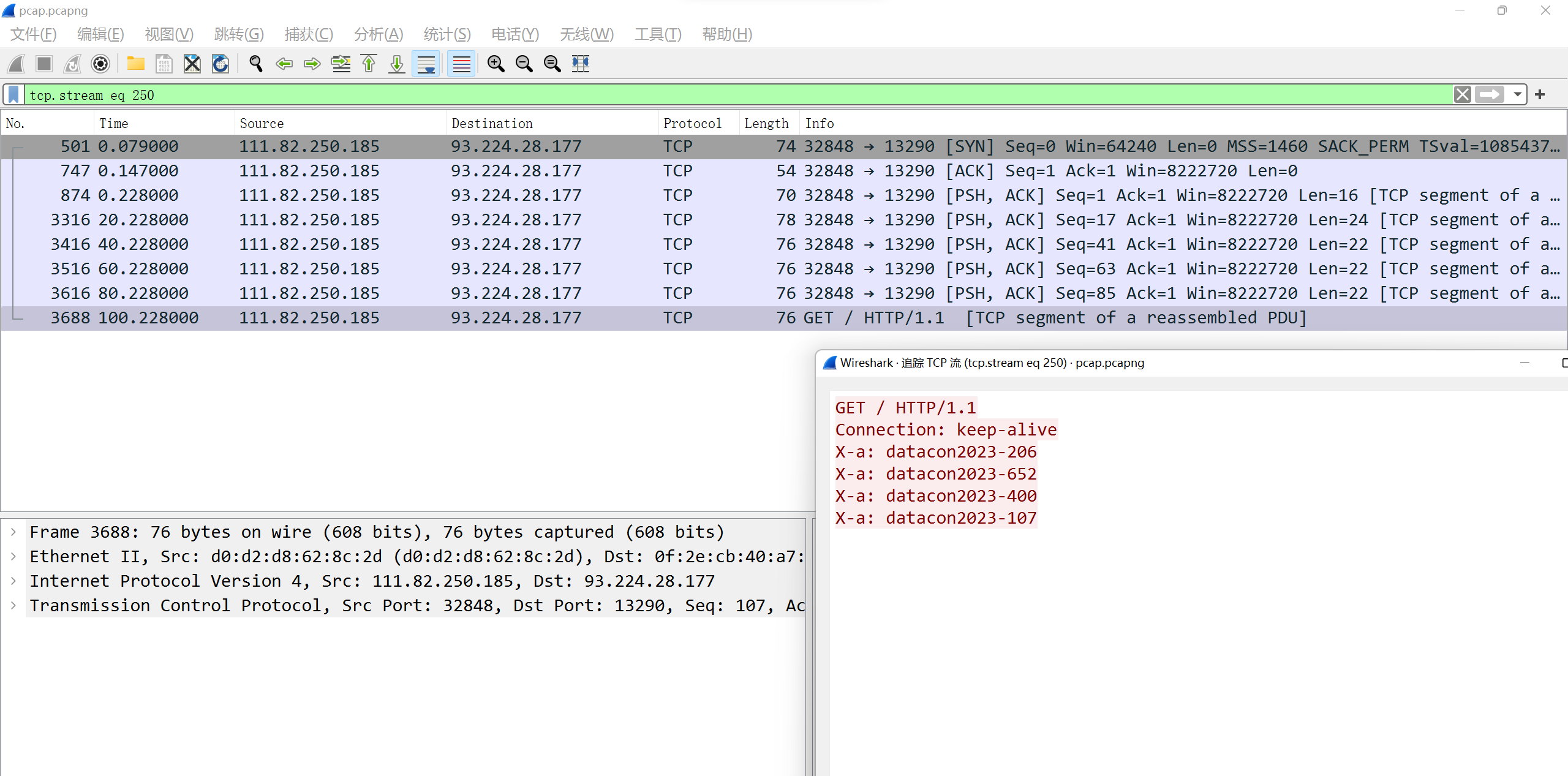
for packet in tls_cap: try: source_ip = packet.ip.src if source_ip notin target: tls_list.add(source_ip) except AttributeError: pass
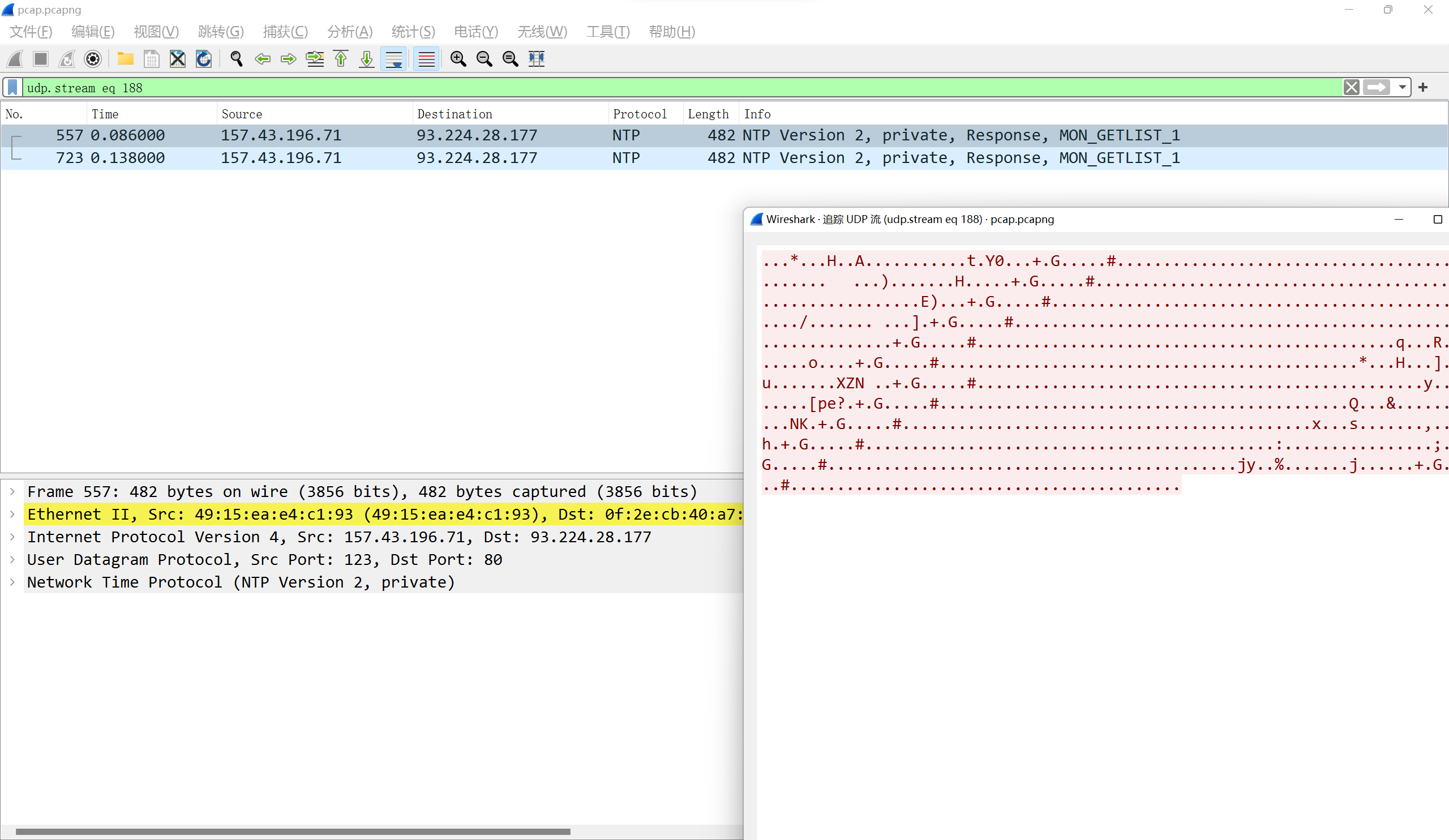
for packet in ntp_cap: try: source_ip = packet.ip.src if source_ip notin target: ntp_list.add(source_ip) except AttributeError: pass
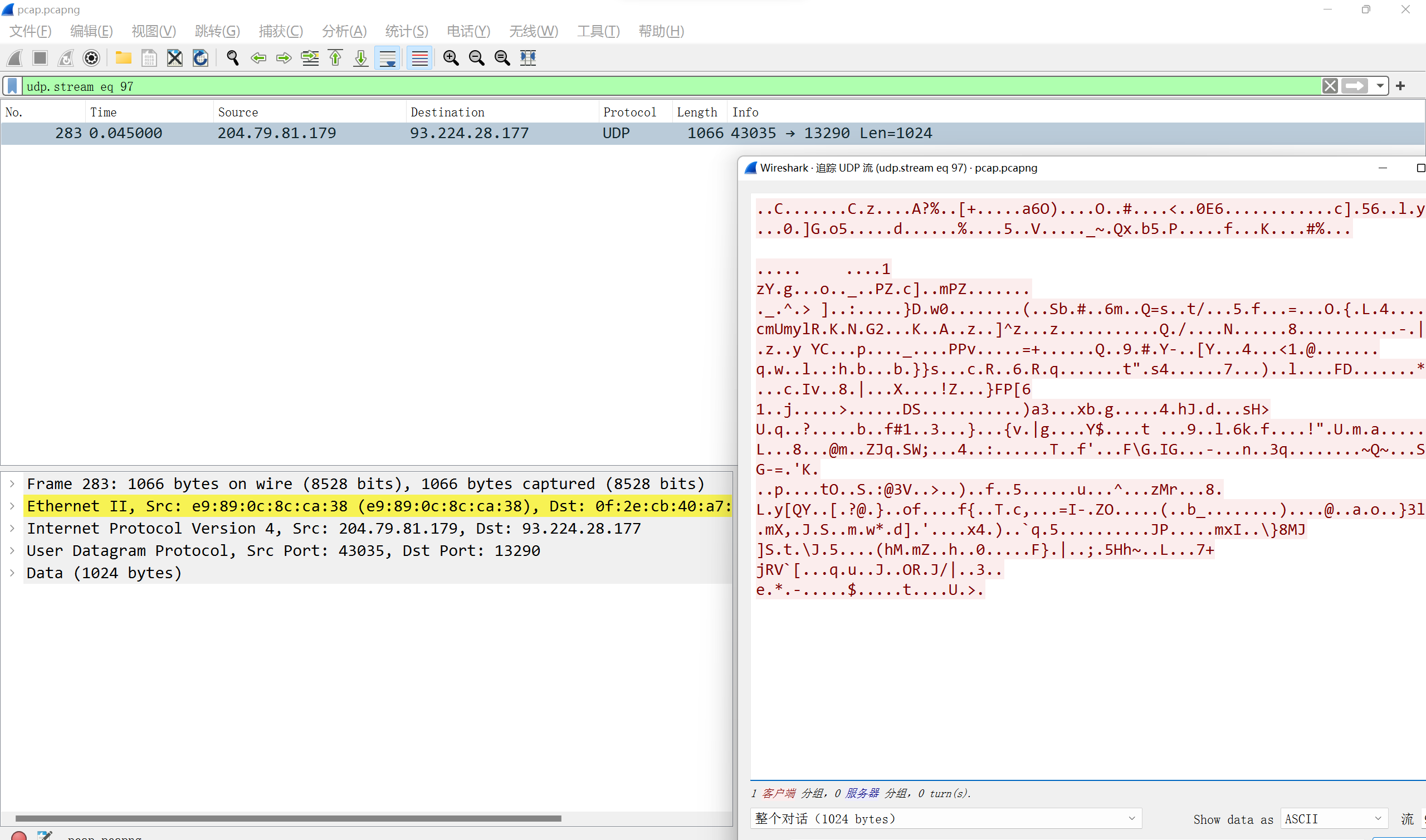
for packet in udp_cap: try: source_ip = packet.ip.src if source_ip notin ntp_list and source_ip notin target: udp_list.add(source_ip) except AttributeError: pass
wget_lines = set() withopen('honeylog.json', 'r') as file: for line in file: line = line.strip() if'wget 'in line or'wget%'in line or'wget+'in line: begin_index=line.find('wget') ll=[len(line)] if line.find(';')!=-1: ll.append(line.find(';')) if line.find(')')!=-1: ll.append(line.find(')')) end_index = min(ll) wget_lines.add(line[begin_index:end_index])
# 将满足条件的行写入2.txt withopen('2.txt', 'w') as file: file.write('\n'.join(wget_lines))
# 读取文件 withopen('honeylog.json', 'r') as file: # 逐行读取 for line in file: if'caesar'in line: try: data = json.loads(line) src_ip = data.get('src_ip') if src_ip: caesar_set.add(src_ip) except: pass if'koba'in line: try: data = json.loads(line) src_ip = data.get('src_ip') if src_ip: koba_set.add(src_ip) except: pass
withopen('md5_file.txt','w') as f: f.write('82f485f6d3dbad747ef307158fc7ea48:') f.write(','.join(caesar_set)) f.write('\n') f.write('e4d87fc7fd025213a86b0db38b147375:') f.write(','.join(koba_set))
q1=open('q1_answer.txt','r') q1.readline() q1.readline() for i in q1.readline().strip().split(','): url_set.add(i) q1.readline() for i in q1.readline().strip().split(','): url_set.add(i) q1.close()
q3='153.97.92.169' withopen('q4_answer.txt','w') as f: f.write(q3) f.write('\n') f.write(','.join(url_set)) f.write('\n')
得到25%的分数。
邮件安全
题目二:新型邮件炸弹攻击
编写脚本,提取前10000权重的网址。
1 2 3 4 5 6 7 8 9 10
mails=[] withopen('top_mail.csv','r') as file: for i in file: a=i.split(',') ifint(a[0])>10000: break else: mails.append(a[1]) withopen('top_10000_mails.txt','w') as f: f.write(''.join(mails))